Self-Supervised Models are Continual Learners
录用信息
录用于CVPR‘22
问题背景:
在自监督学习(SSL)引领表示学习的目前,增量式的自监督表示学习仍然研究不多。本文调查了6种SSL方法经过作者的改进后在增量学习的3种基准下(类增量,数据增量,域增量)进行调查。发现在类增量学习下,SSL增量表示学习比有监督表示学习更优。
设置的3种基准分别是:(1)类增量:这里的类别只用于划分数据集,类别标签对模型不可见(即保证是无监督的);(2)数据增量:不考虑类别关系,只是把数据按批次增加,比较符合现实情况。实验中把数据集打乱再随机划分,因此一个phase内可能包含所有类别;(3)域增量:增量的phase是按照图像的domain划分。
方法概述
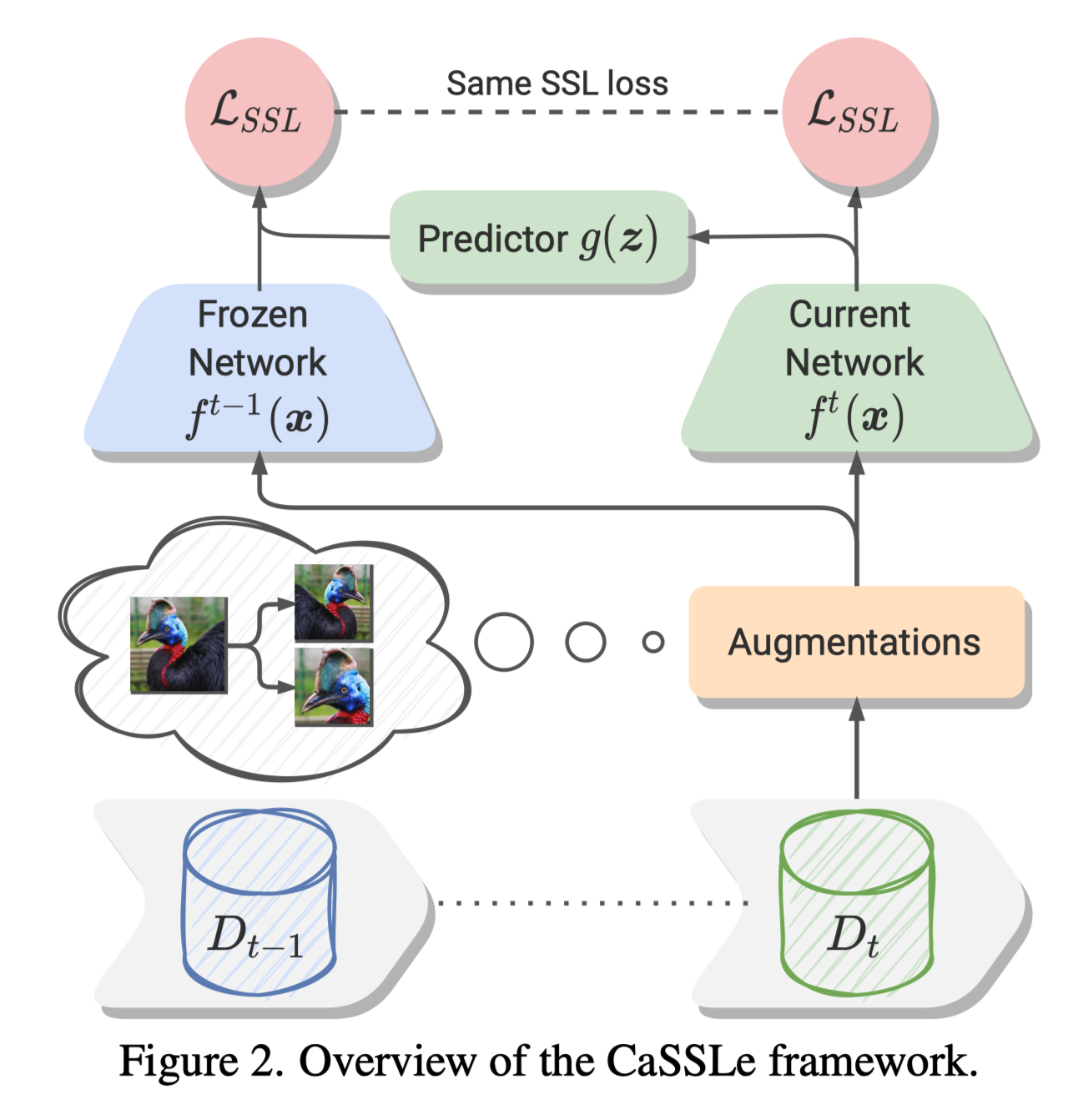
自监督学习的原理是使有相同语义的图像有相似的表示。通常,对图像实例使用数据增强得到正样本图像,其他作为负样本图像。
本文将自监督学习拓展到连续学习的主要思想是:这种语义不变性关于参数状态也是不变的(即不遗忘),SSL被拓展到旧特征空间以及新特征空间。
连续自监督学习核心:学习跨状态不变特征
首先,为了保证新特征可以包含旧特征的信息,本文使用了一个预测头将从新特征空间投影至旧特征空间,然后使用知识蒸馏从中预测。知识蒸馏损失就保持与SSL使用的损失一致即可,好处就是方便简单:
预测头的使用使得可以具有更高可塑性,同时保证的稳定性。
最终的损失为:
其中分别是一个实例的两个视图的特征。
实验概述
实验的核心内涵就是(1)方便的兼容已有SSL方法(2)性能在类增量的基准下表现很好
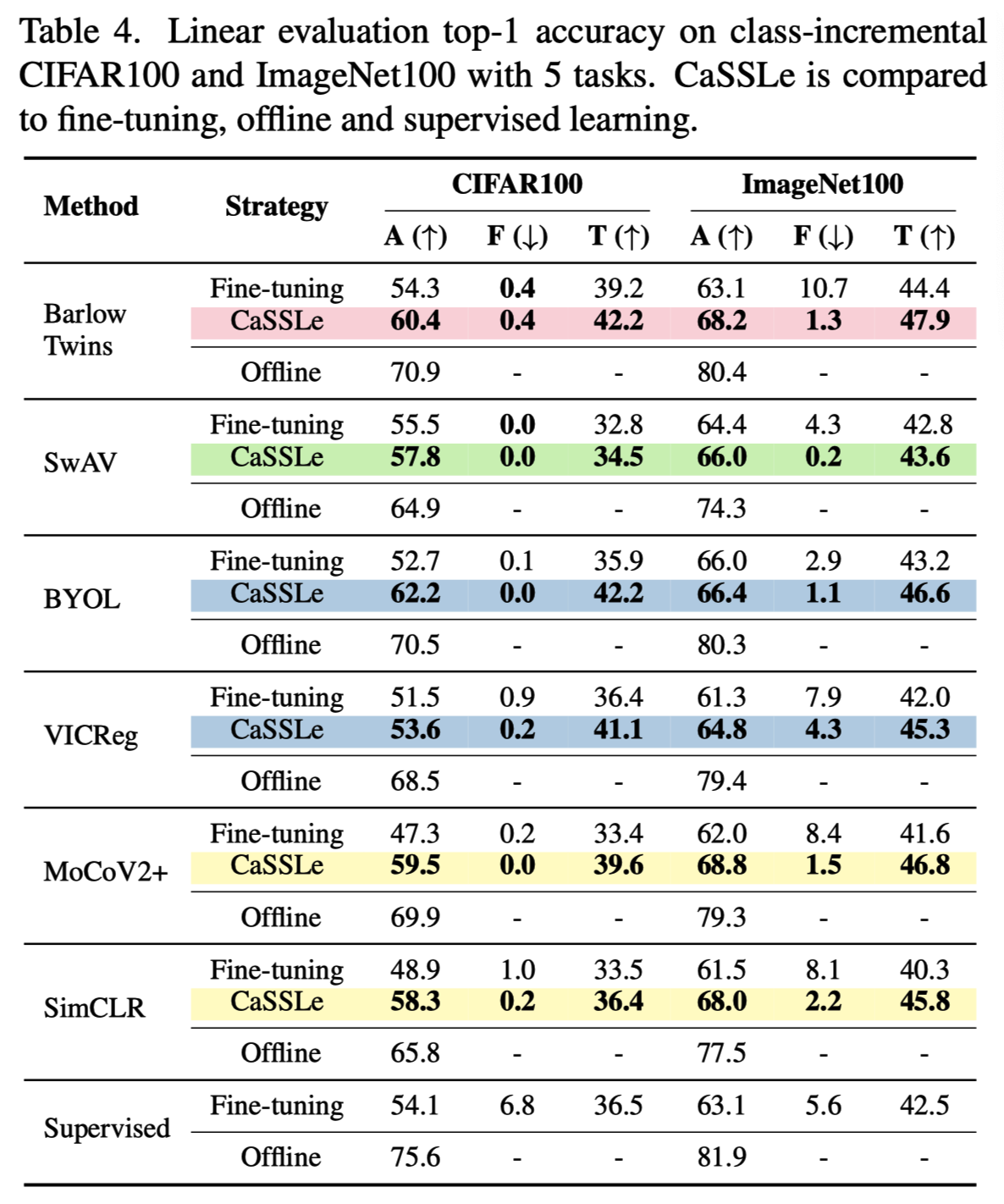
实验的核心比较方法是应用到某种SSL方法后,对比该SSL的Fine-tuning有提升,尽量靠近Offline的上界。比有监督的Fine-tuning也要高。这样就说明了他的价值。在对比数据增量和域增量的基准,只能做到比相同SSL方法Fine-tuning有提升,无法超过监督的Fine-tuning。也可以说明具有一定价值。注意验证方法与有监督的连续学习不同,本文使用的是Linear Evaluation Accuracy(LEA),即在所以无监督增量学习完成后,才获得所有标签信息,只用于微调分类器。最终报告的是平均LEA。
此外还开展了一些有意义的额外实验,比如某些设定下使用更长时间只在intial task进行SSL学习也有可能会比增量SSL更好。以及半监督和下游测试,也使得论文加分不少。
算法伪代码:

我的评价
- 优点:方法较简单,体现了极强的写作技巧(流畅行文和思想高度概括)和实验工作量(非常详细,指标也多),是无监督连续学习的一篇好文章。
- 缺点:性能可提升空间很大。比如在数据增量和域增量上没有超过有监督设定,以及消融中交换视图(,即A视图在新特征空间,B视图在旧特征空间)导致性能下降也说明方法学习到的跨状态不变性不够鲁棒。同样,更长的1/5线下训练有时更好也说明可提升空间较大。此外所有实验基于5步增量,实在是有些少,说明作者在更长距离的实验中可能遭遇尴尬的结果。