权值初始化
1. 梯度消失与爆炸
对于一个没有激活函数(先不考虑激活函数)的多层神经网络,参数的导数可以计算如下
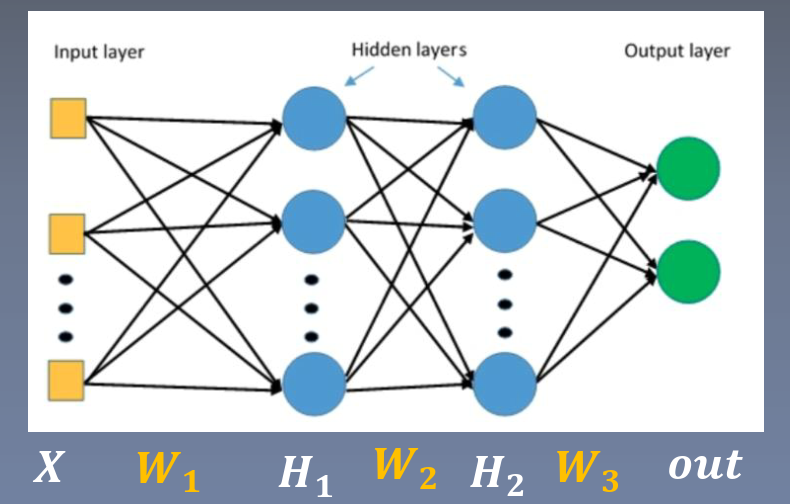
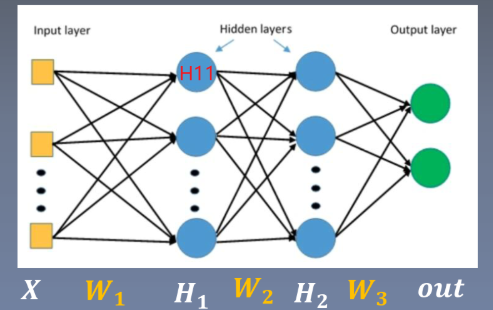
因此参数的导数与隐藏层H1的输出值有关:
梯度消失:
梯度爆炸:
实验代码:
1 | import os |
这里我们构造了一个100层,每一层有256个神经元的全连接线性网络,参数初始化用的是标准正态分布的方法。在随机生成了一个batch_size=16的,满足标准正态分布的输入,观察模型输出。
1 | tensor([[nan, nan, nan, ..., nan, nan, nan], |
发现输出变成了nan(过大或者过小,超出当前精度范围)。我们改一下代码,判断在前向传播中什么时候参数变成了nan(观察每一层参数的标准差)。
1 | import os |
代码运行结果如下:
1 | layer:0, std:15.959932327270508 |
我们发现第31层的参数的标准差变成了无穷。每一层的标准差都在逐渐变大,直到第31层达到了nan。
我们来研究一下,为什么用标准正态分布设置的输入和参数会在前向传播过程中逐渐变大,最终爆炸。
下面是一些数学基础:
若与独立,则有以下结论:
-
-
-
-
若 ,则
X和W都是零均值,标准差为1的标准正态分布,且X和W相互独立。
于是,我们就发现了每经过一层传播,数据的标准差就扩大倍,也就是数据之间开始扩散。上面我们的实验中,n=256,从各层参数的标准差打印信息来看,确实是每一层的标准差扩大15倍的关系。
为了防止各层的标准差在前向传播的过程中逐渐变大,一个好的方法是将每一层的参数的标准差设为1/n,则每一层输出的标准差都能位置在1附近,解决了参数爆炸的问题。
我们重新改一下代码如下:
1 | import os |
运行结果如下:
1 | layer:0, std:0.9974957704544067 |
我们看到,已经解决了参数爆炸的问题。我们以上实现都是基于没有激活函数的情况考虑的,现在我们加上激活函数(选择为tanh),再观察输出。
1 | import os |
运行结果如下:
1 | layer:0, std:0.6273701786994934 |
可以发现,添加了激活函数以后,每一层数据的标准差逐渐减小,这是我们不希望看到的。
2. Xavier方法与Kaiming方法
2.1 Xavier方法
在论文[1]中,提出了一种参数初始化的方法,适用于饱和激活函数,如Sigmoid,Tanh
是第层的神经元个数,是第层的神经元个数
并且,即是服从对称均匀分布的,可以反解出的值,得到:
其实可以发现,当时,和上面的方法是一样的,Xavier方法只是考虑了前后层神经元不等的情况,取了一个平均值。
另外,加上激活函数后,由于数据在通过激活函数之前和通过激活函数之后的标准差会有变化:
1 | x = torch.randn(10000) |
1 | gain:1.5982500314712524 |
通过实验,可以发现tanh输入和输出标准差的比值是gain = 1.6左右,即输出比输入应该是1/gain。
所以说,经过激活函数,数据的标准差会被乘上一个增益(1/gain),这个增益会造成数据标准差一致性被破坏,因此在初始化参数时,应该把激活函数的影响考虑进去。
在考虑了激活函数之后,参数的分布应该为:
,则
1 | import os |
输出结果如下:
1 | layer:0, std:0.7478928565979004 |
可以看到,采用Xavier参数初始化方法后,采用tanh激活函数的神经网络每一层参数的标准差都维持在了0.6左右。
通常,我们还可以使用pytorch提供的函数自动为我们提供gain值。
1 | nn.init.calculate_gain(nonlinearity, param=None) |
主要功能:返回给定非线性函数的建议增益值。数值如下:
| nonlinearity | gain |
|---|---|
| Linear / Identity | 1 |
| Conv{1,2,3}D | 1 |
| Sigmoid | 1 |
| Tanh | |
| ReLU | |
| Leaky Relu |
主要参数
- nonlinearity: 激活函数名称
- param: 激活函数的参数,如Leaky ReLU的negative_slop
使用如下:
1 | import os |
或者我们也可以直接使用Pytorch提供的方法进行Xavier参数初始化:
1 | import os |
输出结果如下:
1 | layer:0, std:0.7571136355400085 |
2.2 Kaiming方法
在论文[2]中,提出了一种参数初始化的方法,适用于非饱和激活函数:ReLU及其变种(如Leaky ReLU,PReLU,RReLU)
对于ReLU:,
发现了吗?由于ReLU这种函数只有正半轴,相比于tanh这种饱和对称函数,方差就要减半。
对于ReLU的变种:,
其中a为负半轴的斜率
并且采用0均值的正态分布(均匀分布也行)
使用Kaiming方法初始化的代码如下所示:
1 | import os |
输出结果如下:
1 | layer:0, std:0.826629638671875 |
同样我们可以使用Pytorch提供的Kaiming初始化方法:
1 | import os |
输出结果也是相同的:
1 | layer:0, std:0.826629638671875 |
3. 常用初始化方法
十种初始化方法
- Xavier均匀分布
- Xavier正态分布
- Kaiming均匀分布
- Kaiming正态分布
- 均匀分布
- 正态分布
- 常数分布
- 正交矩阵初始化
- 单位矩阵初始化
- 稀疏矩阵初始化
参考文献
Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]//Proceedings of the thirteenth international conference on artificial intelligence and statistics. 2010: 249-256. ↩︎
He K, Zhang X, Ren S, et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1026-1034. ↩︎