模型保存与加载
1. PyTorch中对象的保存与加载
1.1 torch.save
1 | torch.save(obj, f) |
主要参数:
- obj:对象
- f:输出路径
1.2 torch.load
1 | torch.load(f, map_location=None) |
主要参数
- f:文件路径
- map_location:指定存放位置, cpu or gpu
2. PyTorch中模型的保存
以下实验要保存的网络为:
1 | import torch |
2.1 方法一:保存整个Module
1 | torch.save(net, path) |
将整个网络打包保存下来,比较省事但是比较耗时耗内存。
2.2 方法二:保存模型参数
1 | state_dict = net.state_dict() |
把网络的所有权值(用state_dict()获取)保存下来
我们看看state_dict函数
1 | state_dict(destination=None, prefix='', keep_vars=False) |
功能:返回包含模块整个状态的字典。包括参数和持久缓冲区(例如运行平均值)。键是相应的参数和缓冲区名称。
加载模型时需要重新构建网络然后加载state_dict。比较省内存,保存的速度也比较快。推荐这种方法。
2.3 保存模型实验
1 | net = LeNet2(classes=2019) |
输出:
1 | 训练前: tensor([[[ 0.0840, 0.1148, 0.0477, 0.0700, -0.0106], |
保存为如下两个文件:


3. PyTorch中模型的加载
3.1 方法一:加载整个Module
实验:
1 | path_model = "./model.pkl" |
输出:
1 | tensor([[[20191104., 20191104., 20191104., 20191104., 20191104.], |
3.2 方法二:加载模型参数
使用load_state_dict函数加载模型参数
1 | load_state_dict(state_dict: Dict[str, torch.Tensor], strict: bool = True) |
功能:将参数和缓冲区从state_dict复制到此模块及其子模块中。如果strict为True,则state_dict的键必须与此模块的state_dict()函数返回的键完全匹配。
实验:
1 | net_new = LeNet2(classes=2019) |
输出:
1 | 加载前: tensor([[[ 0.0452, -0.0556, 0.0299, 0.1078, 0.0888], |
可以看到把所有的权值都加载进网络里了
4. 断点续训练
为了防止训练过程由于意外情况退出而丢失训练数据,可以设置周期checkpoints,保存当前训练进度,以便于下一次直接从checkpoints开始训练。
checkpoint应该包括下面信息(但不限于):
1 | checkpoint = { |
4.1 断点保存
实验:
1 | import os |
输出:
1 | Training:Epoch[000/010] Iteration[010/010] Loss: 0.6852 Acc:54.37% |
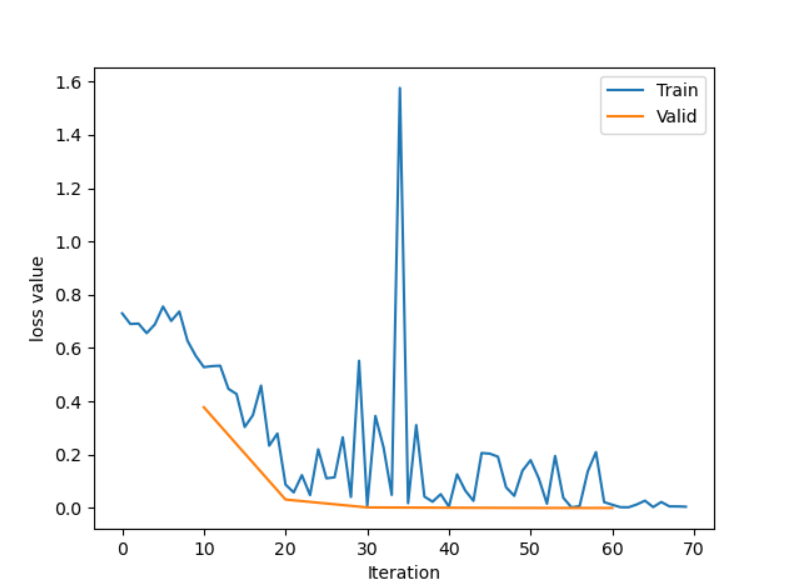
checkpoints的设计如下,checkpoint_interval = 5,所以我们保存了Epoch=5的数据
1 | if (epoch+1) % checkpoint_interval == 0: |
4.2 断点加载
实验:
1 | import os |
输出:
1 | Training:Epoch[005/010] Iteration[010/010] Loss: 0.0406 Acc:99.38% |
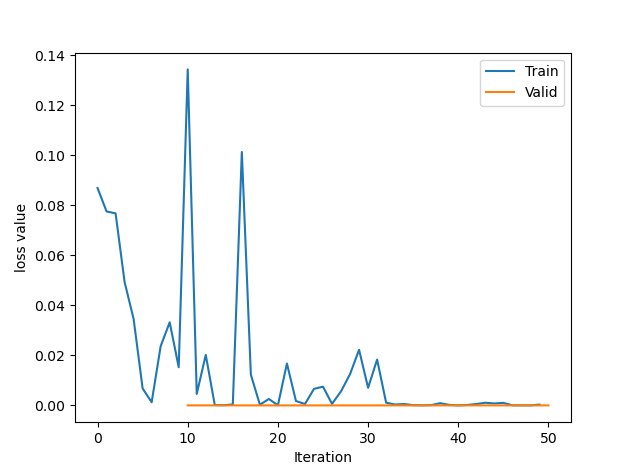
断点加载设置如下
1 | path_checkpoint = "./checkpoint_4_epoch.pkl" |