模型finetune
1. 迁移学习
Transfer Learning:机器学习分支,研究源域(source domain)的知识如何应用到目标域(target domain)
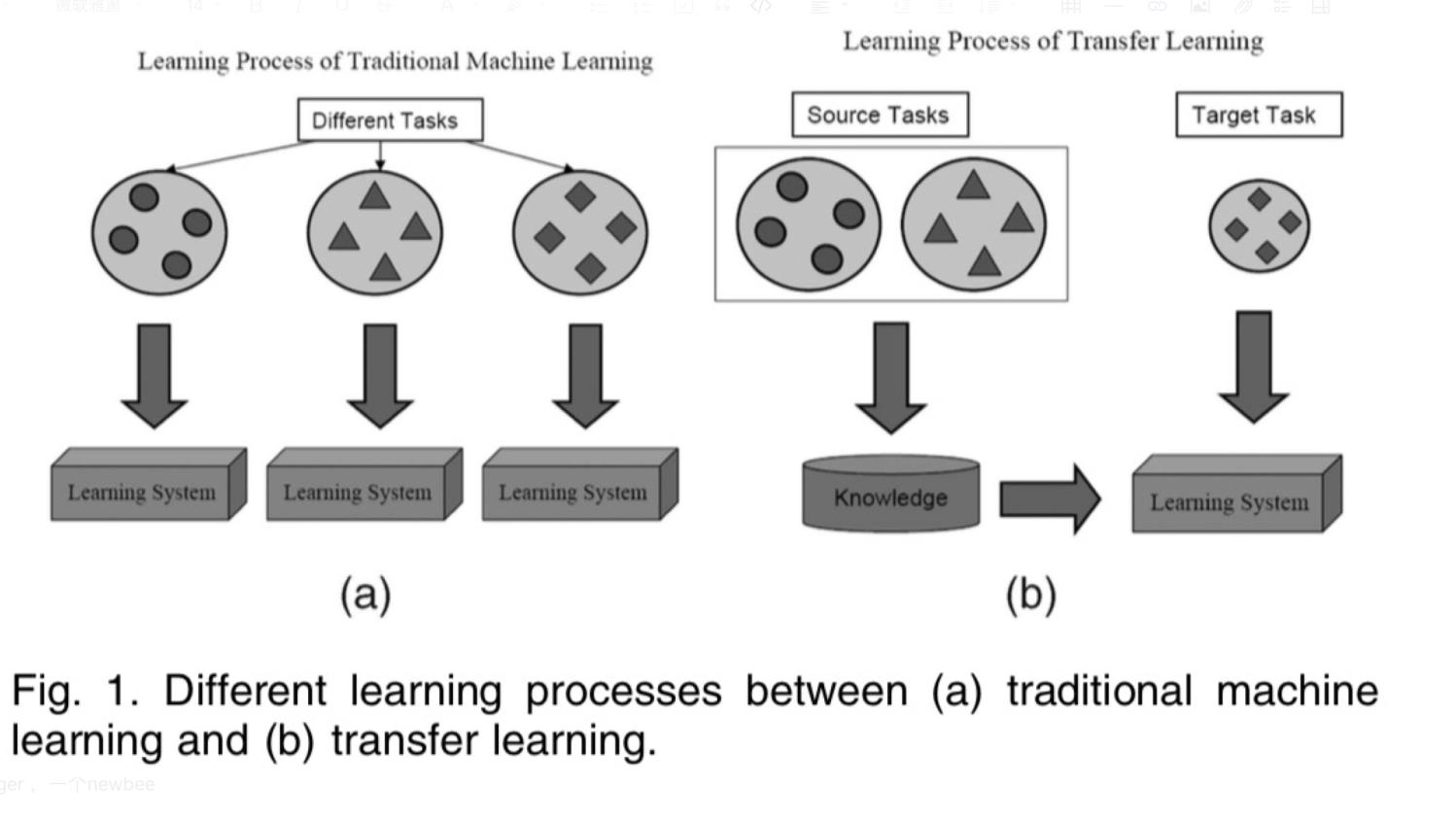
模型微调是属于迁移学习的,但迁移学习更多是研究目标域无标注的情况
2. 模型微调
模型微调步骤:
- 获取预训练模型参数
- 加载模型(load_state_dict)
- 修改输出层
模型微调训练方法:
- 固定预训练的参数(令requires_grad =False或lr=0)
- 浅层网络使用较小的学习率(params_group)
实验:
Finetune Resnet-18 用于二分类
蚂蚁蜜蜂二分类数据
训练集:各120~张 验证集:各70~张
这是一个很小的训练集样本,我们只能在预训练参数上做finetune实现蚂蚁蜜蜂二分类
Resnet-18数据下载
数据:https://download.pytorch.org/tutorial/hymenoptera_data.zip
模型: https://download.pytorch.org/models/resnet18-5c106cde.pth
-
首先构建数据集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35class AntsDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.label_name = {"ants": 0, "bees": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 给一个index打开一张图片,打开图片在这里完成,避免显存爆炸
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir): # os.walk返回(当前文件夹路径,子文件夹路径,当前文件夹文件名)
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir)) # 获得路径下的所有文件名
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) # 只要JPG文件
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name) # 获得JPG文件的完整路径
label = ants_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info # 返回的是所有图片的路径还有对应的类别 -
观察resnet18网络结构:
通过
summary(resnet18_ft, (3, 224, 224), device='cpu')可以打印出网络结构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 44.59
Estimated Total Size (MB): 107.96
----------------------------------------------------------------最后一层是1000类的,对应imagenet的1000类任务。很显然我们需要修改最后一个全连接层使其适应我们的二分类任务(如果更优良的finetune我们可以从更早的部分开始改造,比如最后两个卷积层可以缩减特征图数量)
-
实验代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from tools.my_dataset import AntsDataset
from tools.common_tools import set_seed
import torchvision.models as models
from torchsummary import summary
BASEDIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("use device :{}".format(device))
set_seed(1) # 设置随机种子
label_name = {"ants": 0, "bees": 1}
# 参数设置
MAX_EPOCH = 25
BATCH_SIZE = 16
LR = 0.001
log_interval = 10
val_interval = 1
classes = 2
start_epoch = -1
lr_decay_step = 7
# ============================ step 1/5 数据 ============================
data_dir = os.path.join(BASEDIR, "..", "hymenoptera_data")
train_dir = os.path.join(data_dir, "train")
valid_dir = os.path.join(data_dir, "val")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = AntsDataset(data_dir=train_dir, transform=train_transform)
valid_data = AntsDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
# 1/3 构建模型
resnet18_ft = models.resnet18()
# 2/3 加载参数
path_pretrained_model = os.path.join(BASEDIR, "..", "resnet18-5c106cde.pth")
state_dict_load = torch.load(path_pretrained_model)
resnet18_ft.load_state_dict(state_dict_load)
# 法1 : 冻结卷积层
flag_1 = 0
# flag_1 = 1
if flag_1:
for param in resnet18_ft.parameters():
param.requires_grad = False
# 3/3 替换fc层
num_ftrs = resnet18_ft.fc.in_features
resnet18_ft.fc = nn.Linear(num_ftrs, classes)
resnet18_ft.to(device)
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
# 法2 : conv 小学习率
flag_2 = 0
# flag_2 = 1
if flag_2:
fc_params_id = list(map(id, resnet18_ft.fc.parameters())) # 返回的是全连接层parameters的内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters()) # 非全连接层parameters的parameters记为base_params
optimizer = optim.SGD([
{'params': base_params, 'lr': LR*0.5}, # 非最后一层fc的参数设置为小学习率
{'params': resnet18_ft.fc.parameters(), 'lr': LR}], momentum=0.9) # 最后一层fc的参数设置为大学习率
else:
optimizer = optim.SGD(resnet18_ft.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
resnet18_ft.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = resnet18_ft(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().cpu().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
resnet18_ft.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = resnet18_ft(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().cpu().sum().numpy()
loss_val += loss.item()
loss_val_mean = loss_val/len(valid_loader)
valid_curve.append(loss_val_mean)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_mean, correct_val / total_val))
resnet18_ft.train()
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show() -
选择flag_1 = 0,flag_2 = 0,所有参数都用同一个学习率训练:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51use device :cuda
Training:Epoch[000/025] Iteration[010/016] Loss: 0.6680 Acc:56.25%
Valid: Epoch[000/025] Iteration[010/010] Loss: 0.3331 Acc:89.54%
Training:Epoch[001/025] Iteration[010/016] Loss: 0.3402 Acc:84.38%
Valid: Epoch[001/025] Iteration[010/010] Loss: 0.2071 Acc:95.42%
Training:Epoch[002/025] Iteration[010/016] Loss: 0.2358 Acc:89.38%
Valid: Epoch[002/025] Iteration[010/010] Loss: 0.1689 Acc:95.42%
Training:Epoch[003/025] Iteration[010/016] Loss: 0.1704 Acc:95.00%
Valid: Epoch[003/025] Iteration[010/010] Loss: 0.1962 Acc:95.42%
Training:Epoch[004/025] Iteration[010/016] Loss: 0.1556 Acc:95.00%
Valid: Epoch[004/025] Iteration[010/010] Loss: 0.2022 Acc:94.77%
Training:Epoch[005/025] Iteration[010/016] Loss: 0.1680 Acc:95.00%
Valid: Epoch[005/025] Iteration[010/010] Loss: 0.1848 Acc:94.77%
Training:Epoch[006/025] Iteration[010/016] Loss: 0.1485 Acc:95.00%
Valid: Epoch[006/025] Iteration[010/010] Loss: 0.1658 Acc:94.77%
Training:Epoch[007/025] Iteration[010/016] Loss: 0.1599 Acc:92.50%
Valid: Epoch[007/025] Iteration[010/010] Loss: 0.1643 Acc:95.42%
Training:Epoch[008/025] Iteration[010/016] Loss: 0.1546 Acc:94.38%
Valid: Epoch[008/025] Iteration[010/010] Loss: 0.1692 Acc:94.77%
Training:Epoch[009/025] Iteration[010/016] Loss: 0.1429 Acc:94.38%
Valid: Epoch[009/025] Iteration[010/010] Loss: 0.1681 Acc:94.77%
Training:Epoch[010/025] Iteration[010/016] Loss: 0.0998 Acc:96.88%
Valid: Epoch[010/025] Iteration[010/010] Loss: 0.1713 Acc:94.77%
Training:Epoch[011/025] Iteration[010/016] Loss: 0.0908 Acc:96.25%
Valid: Epoch[011/025] Iteration[010/010] Loss: 0.1784 Acc:94.12%
Training:Epoch[012/025] Iteration[010/016] Loss: 0.1525 Acc:94.38%
Valid: Epoch[012/025] Iteration[010/010] Loss: 0.1941 Acc:93.46%
Training:Epoch[013/025] Iteration[010/016] Loss: 0.1350 Acc:95.62%
Valid: Epoch[013/025] Iteration[010/010] Loss: 0.1828 Acc:93.46%
Training:Epoch[014/025] Iteration[010/016] Loss: 0.1251 Acc:95.00%
Valid: Epoch[014/025] Iteration[010/010] Loss: 0.1909 Acc:93.46%
Training:Epoch[015/025] Iteration[010/016] Loss: 0.1638 Acc:95.00%
Valid: Epoch[015/025] Iteration[010/010] Loss: 0.1912 Acc:93.46%
Training:Epoch[016/025] Iteration[010/016] Loss: 0.1168 Acc:93.12%
Valid: Epoch[016/025] Iteration[010/010] Loss: 0.1838 Acc:94.12%
Training:Epoch[017/025] Iteration[010/016] Loss: 0.1101 Acc:96.25%
Valid: Epoch[017/025] Iteration[010/010] Loss: 0.1819 Acc:94.12%
Training:Epoch[018/025] Iteration[010/016] Loss: 0.1109 Acc:94.38%
Valid: Epoch[018/025] Iteration[010/010] Loss: 0.1800 Acc:94.12%
Training:Epoch[019/025] Iteration[010/016] Loss: 0.1456 Acc:94.38%
Valid: Epoch[019/025] Iteration[010/010] Loss: 0.1761 Acc:94.12%
Training:Epoch[020/025] Iteration[010/016] Loss: 0.1267 Acc:95.62%
Valid: Epoch[020/025] Iteration[010/010] Loss: 0.1952 Acc:93.46%
Training:Epoch[021/025] Iteration[010/016] Loss: 0.1585 Acc:94.38%
Valid: Epoch[021/025] Iteration[010/010] Loss: 0.1818 Acc:94.12%
Training:Epoch[022/025] Iteration[010/016] Loss: 0.1281 Acc:95.62%
Valid: Epoch[022/025] Iteration[010/010] Loss: 0.1940 Acc:93.46%
Training:Epoch[023/025] Iteration[010/016] Loss: 0.1199 Acc:95.62%
Valid: Epoch[023/025] Iteration[010/010] Loss: 0.1803 Acc:94.12%
Training:Epoch[024/025] Iteration[010/016] Loss: 0.1197 Acc:95.62%
Valid: Epoch[024/025] Iteration[010/010] Loss: 0.1991 Acc:93.46%25个epoch之后,在验证集上的准确率达到了93.46%
![image-20200816101614963]()
-
选择flag_1 = 1,flag_2 = 0,冻结网络参数,只训练最后一个(in=512, out=2)的全连接层:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51use device :cuda
Training:Epoch[000/025] Iteration[010/016] Loss: 0.6931 Acc:55.00%
Valid: Epoch[000/025] Iteration[010/010] Loss: 0.4438 Acc:86.93%
Training:Epoch[001/025] Iteration[010/016] Loss: 0.4306 Acc:82.50%
Valid: Epoch[001/025] Iteration[010/010] Loss: 0.3010 Acc:92.16%
Training:Epoch[002/025] Iteration[010/016] Loss: 0.3172 Acc:85.62%
Valid: Epoch[002/025] Iteration[010/010] Loss: 0.2253 Acc:95.42%
Training:Epoch[003/025] Iteration[010/016] Loss: 0.2561 Acc:90.00%
Valid: Epoch[003/025] Iteration[010/010] Loss: 0.2087 Acc:95.42%
Training:Epoch[004/025] Iteration[010/016] Loss: 0.2222 Acc:92.50%
Valid: Epoch[004/025] Iteration[010/010] Loss: 0.2067 Acc:94.12%
Training:Epoch[005/025] Iteration[010/016] Loss: 0.2443 Acc:91.88%
Valid: Epoch[005/025] Iteration[010/010] Loss: 0.2174 Acc:94.77%
Training:Epoch[006/025] Iteration[010/016] Loss: 0.2268 Acc:90.00%
Valid: Epoch[006/025] Iteration[010/010] Loss: 0.1987 Acc:94.12%
Training:Epoch[007/025] Iteration[010/016] Loss: 0.3340 Acc:85.00%
Valid: Epoch[007/025] Iteration[010/010] Loss: 0.1996 Acc:94.12%
Training:Epoch[008/025] Iteration[010/016] Loss: 0.2242 Acc:92.50%
Valid: Epoch[008/025] Iteration[010/010] Loss: 0.1912 Acc:94.77%
Training:Epoch[009/025] Iteration[010/016] Loss: 0.2115 Acc:93.12%
Valid: Epoch[009/025] Iteration[010/010] Loss: 0.1897 Acc:96.08%
Training:Epoch[010/025] Iteration[010/016] Loss: 0.1615 Acc:95.00%
Valid: Epoch[010/025] Iteration[010/010] Loss: 0.1909 Acc:96.08%
Training:Epoch[011/025] Iteration[010/016] Loss: 0.1864 Acc:91.25%
Valid: Epoch[011/025] Iteration[010/010] Loss: 0.2055 Acc:94.77%
Training:Epoch[012/025] Iteration[010/016] Loss: 0.2330 Acc:90.62%
Valid: Epoch[012/025] Iteration[010/010] Loss: 0.2097 Acc:94.12%
Training:Epoch[013/025] Iteration[010/016] Loss: 0.2370 Acc:91.25%
Valid: Epoch[013/025] Iteration[010/010] Loss: 0.1953 Acc:94.77%
Training:Epoch[014/025] Iteration[010/016] Loss: 0.2184 Acc:91.88%
Valid: Epoch[014/025] Iteration[010/010] Loss: 0.1949 Acc:95.42%
Training:Epoch[015/025] Iteration[010/016] Loss: 0.2500 Acc:90.62%
Valid: Epoch[015/025] Iteration[010/010] Loss: 0.1992 Acc:95.42%
Training:Epoch[016/025] Iteration[010/016] Loss: 0.2139 Acc:91.25%
Valid: Epoch[016/025] Iteration[010/010] Loss: 0.1972 Acc:95.42%
Training:Epoch[017/025] Iteration[010/016] Loss: 0.1920 Acc:93.12%
Valid: Epoch[017/025] Iteration[010/010] Loss: 0.2002 Acc:95.42%
Training:Epoch[018/025] Iteration[010/016] Loss: 0.2147 Acc:91.88%
Valid: Epoch[018/025] Iteration[010/010] Loss: 0.1950 Acc:95.42%
Training:Epoch[019/025] Iteration[010/016] Loss: 0.2294 Acc:90.00%
Valid: Epoch[019/025] Iteration[010/010] Loss: 0.1903 Acc:96.08%
Training:Epoch[020/025] Iteration[010/016] Loss: 0.2222 Acc:90.62%
Valid: Epoch[020/025] Iteration[010/010] Loss: 0.2015 Acc:94.77%
Training:Epoch[021/025] Iteration[010/016] Loss: 0.2145 Acc:90.62%
Valid: Epoch[021/025] Iteration[010/010] Loss: 0.1953 Acc:95.42%
Training:Epoch[022/025] Iteration[010/016] Loss: 0.2266 Acc:92.50%
Valid: Epoch[022/025] Iteration[010/010] Loss: 0.2029 Acc:94.12%
Training:Epoch[023/025] Iteration[010/016] Loss: 0.2191 Acc:92.50%
Valid: Epoch[023/025] Iteration[010/010] Loss: 0.1955 Acc:95.42%
Training:Epoch[024/025] Iteration[010/016] Loss: 0.2133 Acc:92.50%
Valid: Epoch[024/025] Iteration[010/010] Loss: 0.2063 Acc:94.77%25个epoch之后,在验证集上的准确率达到了94.77%
![image-20200816102142913]()
-
选择flag_1 = 0,flag_2 =1,对非最后一层fc的参数使用小学习率,对最后一层fc的参数使用大学习率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51use device :cuda
Training:Epoch[000/025] Iteration[010/016] Loss: 0.6802 Acc:55.62%
Valid: Epoch[000/025] Iteration[010/010] Loss: 0.3802 Acc:89.54%
Training:Epoch[001/025] Iteration[010/016] Loss: 0.3788 Acc:83.75%
Valid: Epoch[001/025] Iteration[010/010] Loss: 0.2376 Acc:95.42%
Training:Epoch[002/025] Iteration[010/016] Loss: 0.2667 Acc:88.12%
Valid: Epoch[002/025] Iteration[010/010] Loss: 0.1872 Acc:95.42%
Training:Epoch[003/025] Iteration[010/016] Loss: 0.1985 Acc:93.12%
Valid: Epoch[003/025] Iteration[010/010] Loss: 0.1869 Acc:95.42%
Training:Epoch[004/025] Iteration[010/016] Loss: 0.1730 Acc:95.00%
Valid: Epoch[004/025] Iteration[010/010] Loss: 0.1952 Acc:94.77%
Training:Epoch[005/025] Iteration[010/016] Loss: 0.1882 Acc:92.50%
Valid: Epoch[005/025] Iteration[010/010] Loss: 0.2003 Acc:94.77%
Training:Epoch[006/025] Iteration[010/016] Loss: 0.1756 Acc:91.25%
Valid: Epoch[006/025] Iteration[010/010] Loss: 0.1705 Acc:94.77%
Training:Epoch[007/025] Iteration[010/016] Loss: 0.2252 Acc:90.62%
Valid: Epoch[007/025] Iteration[010/010] Loss: 0.1780 Acc:94.12%
Training:Epoch[008/025] Iteration[010/016] Loss: 0.1844 Acc:93.12%
Valid: Epoch[008/025] Iteration[010/010] Loss: 0.1735 Acc:94.77%
Training:Epoch[009/025] Iteration[010/016] Loss: 0.1627 Acc:94.38%
Valid: Epoch[009/025] Iteration[010/010] Loss: 0.1729 Acc:95.42%
Training:Epoch[010/025] Iteration[010/016] Loss: 0.1139 Acc:95.62%
Valid: Epoch[010/025] Iteration[010/010] Loss: 0.1764 Acc:94.77%
Training:Epoch[011/025] Iteration[010/016] Loss: 0.1217 Acc:95.00%
Valid: Epoch[011/025] Iteration[010/010] Loss: 0.1861 Acc:93.46%
Training:Epoch[012/025] Iteration[010/016] Loss: 0.1791 Acc:93.12%
Valid: Epoch[012/025] Iteration[010/010] Loss: 0.1995 Acc:93.46%
Training:Epoch[013/025] Iteration[010/016] Loss: 0.1668 Acc:93.75%
Valid: Epoch[013/025] Iteration[010/010] Loss: 0.1837 Acc:94.77%
Training:Epoch[014/025] Iteration[010/016] Loss: 0.1576 Acc:93.75%
Valid: Epoch[014/025] Iteration[010/010] Loss: 0.1888 Acc:94.12%
Training:Epoch[015/025] Iteration[010/016] Loss: 0.1972 Acc:91.88%
Valid: Epoch[015/025] Iteration[010/010] Loss: 0.1905 Acc:93.46%
Training:Epoch[016/025] Iteration[010/016] Loss: 0.1500 Acc:92.50%
Valid: Epoch[016/025] Iteration[010/010] Loss: 0.1848 Acc:94.77%
Training:Epoch[017/025] Iteration[010/016] Loss: 0.1329 Acc:95.00%
Valid: Epoch[017/025] Iteration[010/010] Loss: 0.1872 Acc:94.77%
Training:Epoch[018/025] Iteration[010/016] Loss: 0.1408 Acc:94.38%
Valid: Epoch[018/025] Iteration[010/010] Loss: 0.1842 Acc:94.77%
Training:Epoch[019/025] Iteration[010/016] Loss: 0.1764 Acc:92.50%
Valid: Epoch[019/025] Iteration[010/010] Loss: 0.1772 Acc:94.77%
Training:Epoch[020/025] Iteration[010/016] Loss: 0.1561 Acc:93.12%
Valid: Epoch[020/025] Iteration[010/010] Loss: 0.1940 Acc:94.12%
Training:Epoch[021/025] Iteration[010/016] Loss: 0.1719 Acc:93.12%
Valid: Epoch[021/025] Iteration[010/010] Loss: 0.1826 Acc:94.77%
Training:Epoch[022/025] Iteration[010/016] Loss: 0.1609 Acc:93.75%
Valid: Epoch[022/025] Iteration[010/010] Loss: 0.1937 Acc:93.46%
Training:Epoch[023/025] Iteration[010/016] Loss: 0.1482 Acc:94.38%
Valid: Epoch[023/025] Iteration[010/010] Loss: 0.1825 Acc:94.12%
Training:Epoch[024/025] Iteration[010/016] Loss: 0.1505 Acc:95.00%
Valid: Epoch[024/025] Iteration[010/010] Loss: 0.1963 Acc:95.42%25个epoch之后,在验证集上的准确率达到了95.42%
![image-20200816105209289]()


