tensorboard可视化
1. TensorBoard简介与安装
1.1 安装TensorBoard
TensorBoard:TensorFlow中强大的可视化工具

通过pip install future和pip install tensorboard安装tensorboard
1.2 运行TensorBoard
实验代码:
1 | import numpy as np |
运行后,会在py文件目录中生成一个run文件夹,每一次运行会在run文件夹中生成一个子文件夹。
然后在terminal中cd到run文件夹的根目录,输入tensorboard --logdir=./runs命令,就开始运行tensorboard了,在浏览器中可以查看。
1 | TensorFlow installation not found - running with reduced feature set. |
1.3 界面TensorBoard




平滑的作用在于,当曲线噪声非常大时,使用平滑我们可以看出大致的趋势(低通滤波?)
2. TensorBoard使用
2.1 SummaryWriter
1 | import numpy as np |
功能:提供创建event file的高级接口;SummaryWriter类提供了一个高级API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。类异步更新文件内容,这使得训练程序可以调用方法直接从训练循环中向文件中添加数据,而不会减慢训练速度。
主要属性:
- log_dir:设置event file输出文件夹;默认为runs/CURRENT_DATETIME_HOSTNAME
- comment:为默认log_dir添加后缀。如果指定了log_dir,则此参数无效。
- filename_suffix:为log_dir目录中所有event file文件名添加后缀
实验:
1 | import numpy as np |
-
运行
writer = SummaryWriter(),得到输出文件夹如下所示:![image-20200807163509626]()
-
运行
writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678"),得到输出文件夹如下所示:![image-20200807164947430]()
-
运行
riter = SummaryWriter(comment='_scalars', filename_suffix="12345678"),得到输出文件夹如下所示:![image-20200807165126857]()



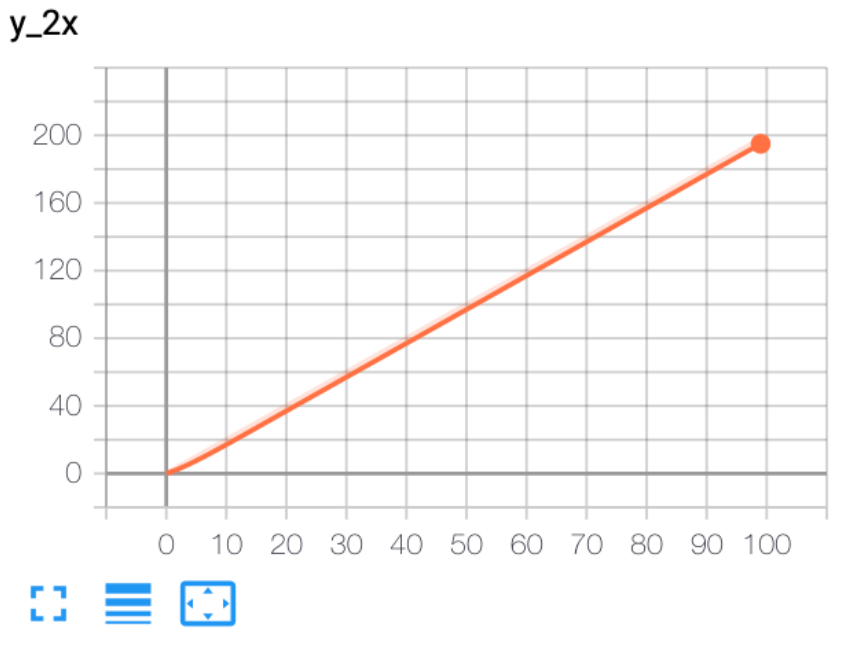
2.1.1 add_scalar
1 | add_scalar(tag, |
功能:将标量数据添加到summary(只能记录一条曲线)
- tag:图像的标签名,图的唯一标识
- scalar_value:要记录的标量
- global_step:x轴
实验:
1 | from torch.utils.tensorboard import SummaryWriter |
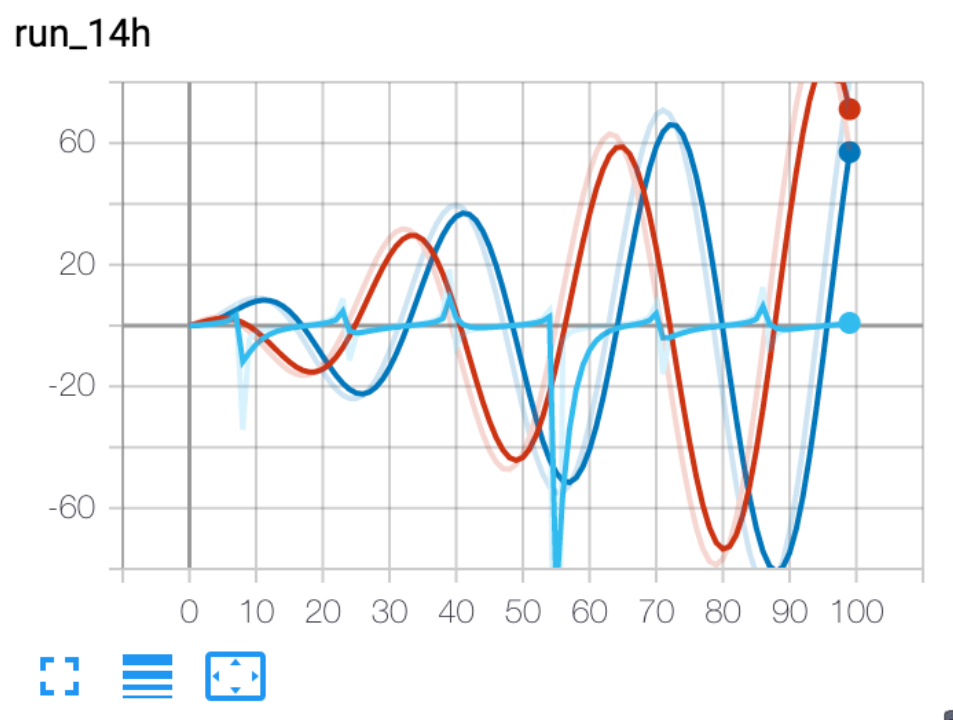
2.1.2 add_scalars
1 | add_scalars(main_tag, |
功能:将许多标量数据添加到summary(记录多条曲线)
- main_tag:该图的标签
- tag_scalar_dict:key是变量的tag,value是变量的值
实验:
1 | from torch.utils.tensorboard import SummaryWriter |
2.1.3 add_histogram
1 | add_histogram(tag, values, |
功能:统计直方图与多分位数折线图
-
tag:图像的标签名,图的唯一标识
-
values:要统计的参数
-
global_step:y轴
-
bins:{‘tensorflow’,‘auto’,‘fd’,…}之一。这决定了直方图条的宽度。您可以在以下位置找到其他选项:https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.html
实验:
1 | import numpy as np |
- matplot输出如下所示(得到两个figure):
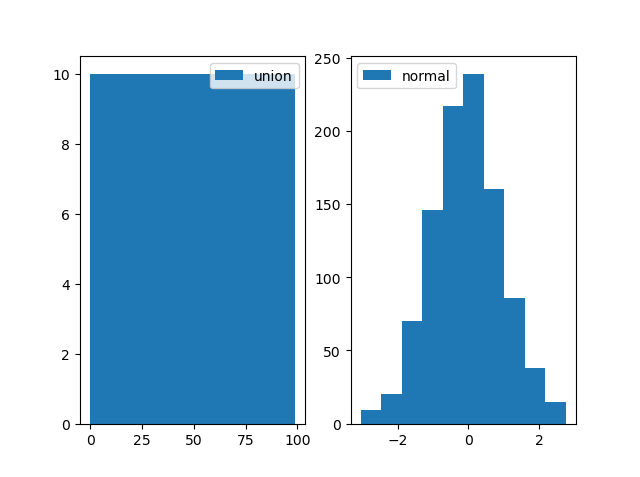
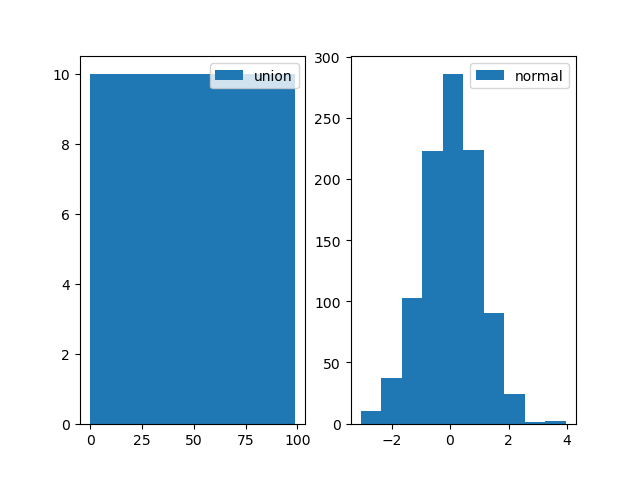
plt.hist默认bin=10,即把直方图分成10个条。对于左图就是[0, 9], [10, 19], …, [90, 99]统计在一起,显然对于每一个bin都有10个数据落入其中;
以下是bin=20的直方图:
![image-20200808190423187]()
![image-20200808190432190]()


打开tensorboard,可以看到下面的直方图。bins=‘tensorflow’(默认),这个bin的计算方式我目前还没看懂。均匀分布的直方图本来应该是平的,但是出现的高低起伏,说明bin是不等宽的,由内部函数动态分配。
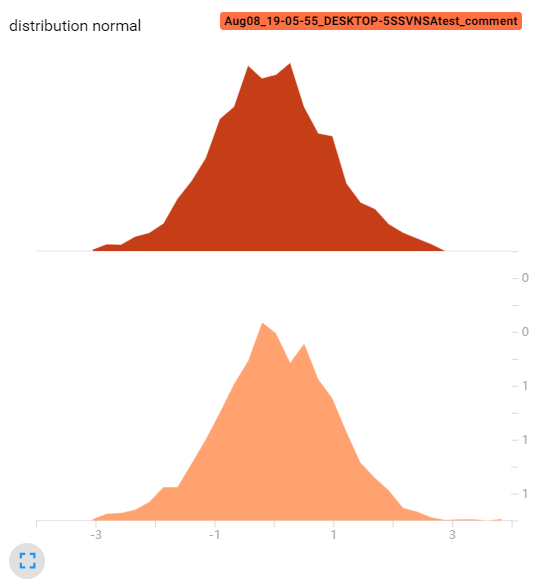
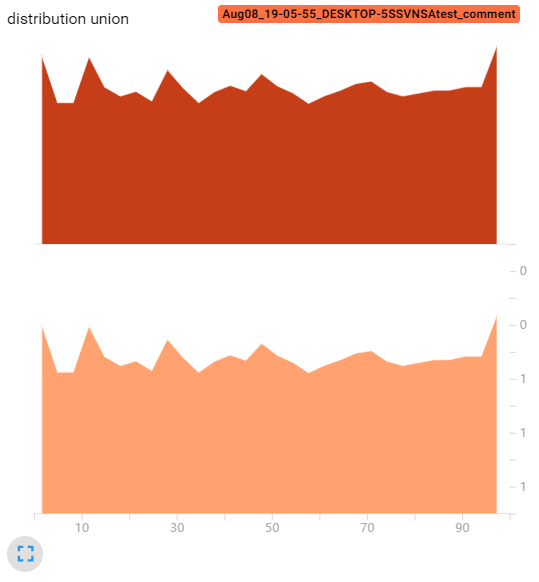
如果我们令bins=10:
1 | writer.add_histogram('distribution union', data_union, x, bins=10) |
tensorboard得到下面直方图:
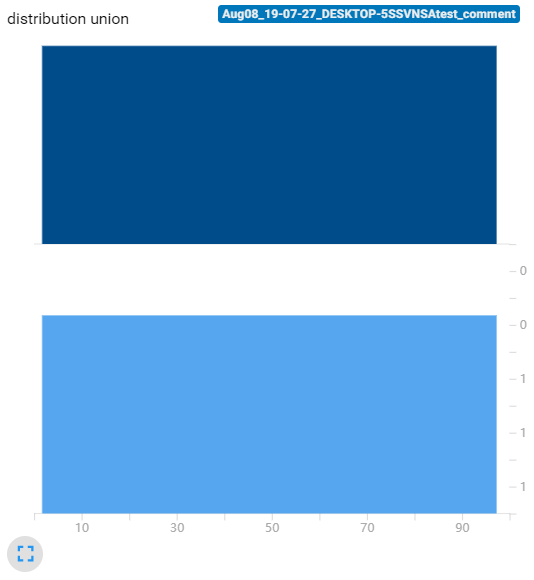
我们可以发现,已经和我们用plt.hist输出的直方图很相似了,唯一还搞不懂的就是纵坐标的计算方式(居然是个小数,其次这个直方图还不是条形的,搞不懂)
以下是bins=20的tensorboard直方图,可以看到随着bins的增加,曲线更加圆滑了(还是搞不懂这个图是怎么来的,直方图却不是条状)
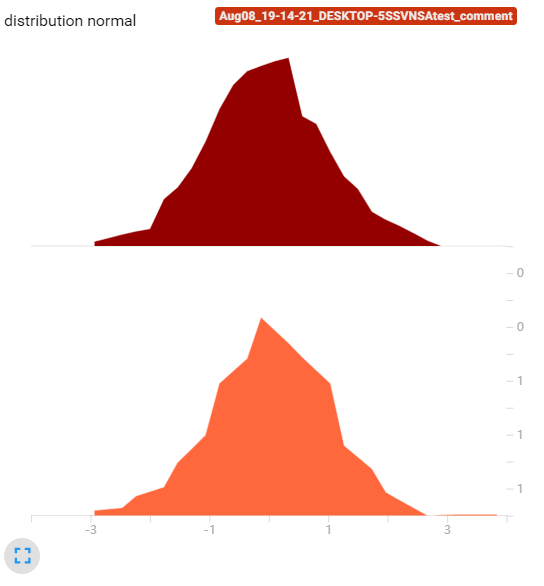
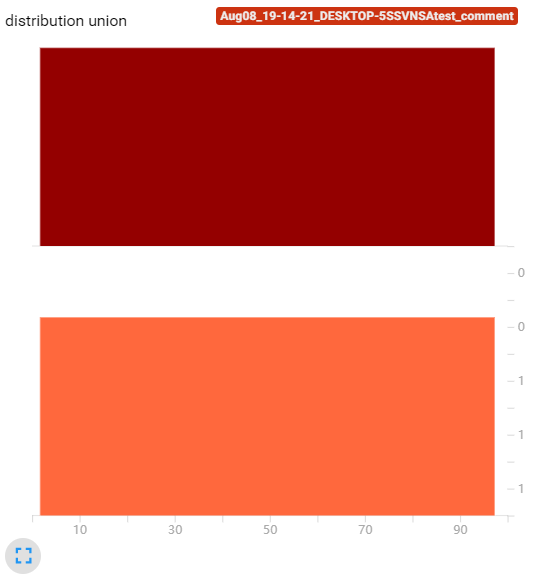
下面是bins=100的tensorboard直方图:
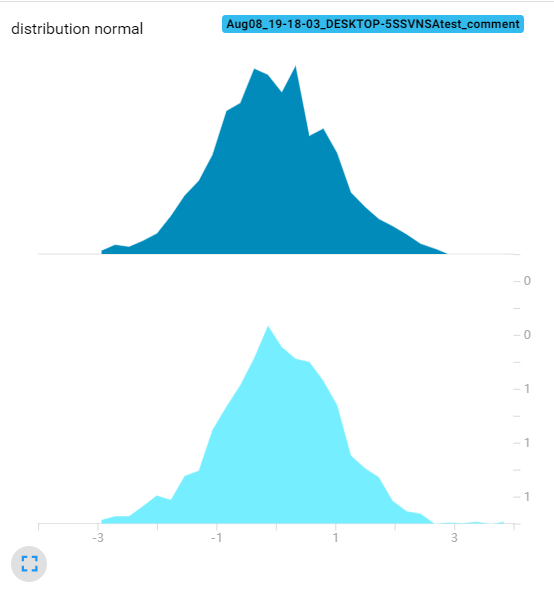
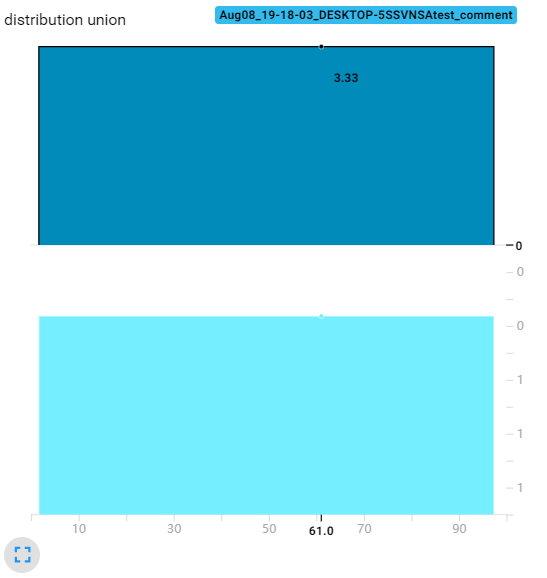
通过以上实验可以发现,bins这个参数就调整精细程度,bins愈大得到的直方图越精细。此外随着bins提高,直方图的值(纵坐标)并没有变化,这也说明了tensorboard的直方图不是传统意义的直方图(传统直方图是统计在bin内数据的数量)
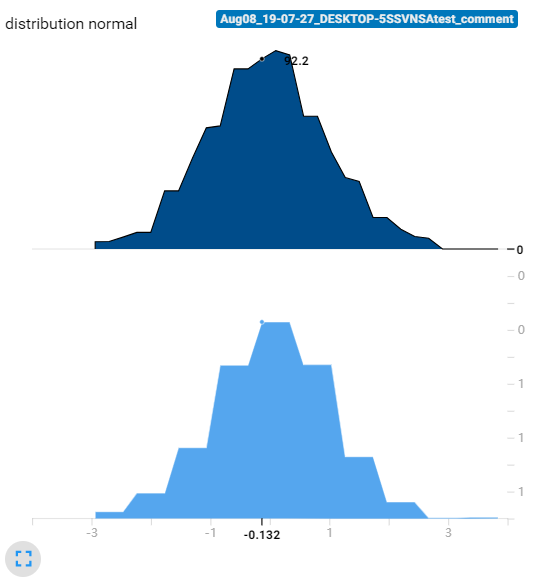
另外,我还发现了,无论bins取多少,tensorboard这个直方图总是有30个采样点(下图展示了无论bins取多少,每个采样的位置都是一样的。可以看到第一个是点是-2.94,第二个点是-2.70)。这30个数据点的值加在一起就约等于样本总体的数据量。像下面这个标准正态分布的30个数据点的数加起来约等于1000。所以这个tensorboard的直方图还是有智慧的。我们不能把他看成传统意义的直方图,纵坐标应该看成在这个横坐标左右区域(比如第一个数据点横坐标是-2.94,第二个是-2.70,那么宽度就是0.24,所以第一个数据点纵坐标的意义是:在[-3.06, -2.82])大概有3.33个数据点。
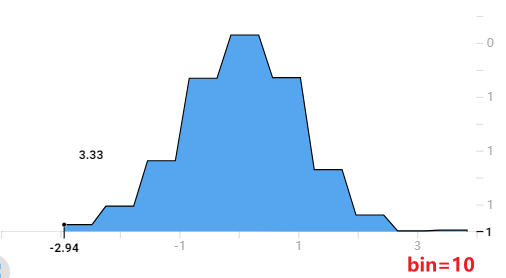
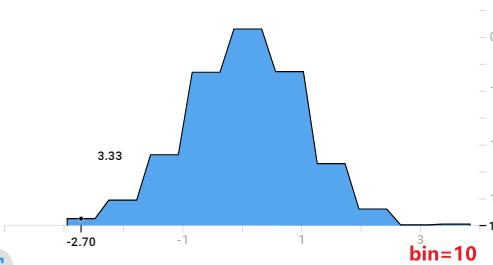
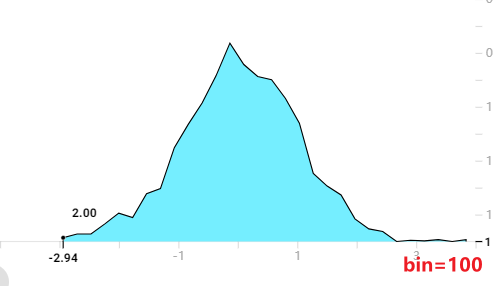
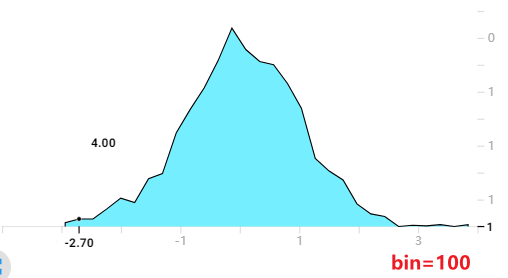
所以我猜测:这个图的计算方法是先按给定的bins参数绘制出直方图,然后对直方图等间隔采样30个数据点,再将这些数据点用折线连接起来。数据点的值做了归一化处理,与bins的数量无关。
2.1.4 实战一: 监控loss, accuracy, weights, gradients
下面是我们之前用Lenet做的的rmb二分类的tensorboard可视化的结果。
实验代码:
1 | import os |
-
Accuracy
![image-20200808215556184]()
![image-20200808215741753]()
-
Loss
![1]()
![image-20200808215811301]()
-
conv1.weight_data
![image-20200808220043248]()
可以看见,conv1层的参数分布还是不错的,方差保持了一致性
-
conv1.weight_grad
![image-20200808220124651]()
conv1层的梯度也可以,在后面梯度变为0的原因有两种:
- 训练完成,loss很小
- 发生梯度弥散,梯度没办法方向传播到前面的网络层
怎么判断呢?可以看loss是否足够低,也可以看最后一层网络层的梯度是否也很小,如果不是说明发生了梯度弥散。
-
fc3.weight_data
![image-20200808220309895]()
-
fc3.weight_grad
![image-20200808220330517]()
最后一层网络层随着迭代的次数,梯度也逐渐变小,说明没有发生梯度回传障碍。








2.1.5 add_image
1 | add_image(tag, |
功能:记录图像
- tag:图像的标签名,图的唯一标识
- img_tensor:图像数据,注意尺度(数据在[0,1]内的自动乘255转为0255的像素值;数据不在[0,1]内的当成0255的像素值)
- global_step:x轴
- dataformats:数据形式,CHW,HWC,HW
实验:
1 | import os |

数据处于[0, 1]范围内,所以会自动乘255转化为像素值

数据处于[0, 1]范围内,所以会自动乘255转化为像素值;所以图片变成了像素值全为255的纯白照片。

数据不处于[0, 1]范围内,且全部数据值为1.1,所以显示出来是黑色的照片

数据处于[0, 1]范围内,所以会自动乘255转化为像素值;但只有一个通道,参数应写为dataformats=“HW”

数据处于[0, 1]范围内,所以会自动乘255转化为像素值;但通道是HWC,参数应写为dataformats=“HWC”
用add_img显示图片需要用鼠标拖动显示相应step的图像
那有没有方法能一次显示所有图片呢?torchvision.utils.make_grid就是答案。
2.1.6 torchvision.utils.make_grid
1 | make_grid(tensor, |
功能:制作网格图像
- tensor:图像数据; 4Dmini-batch的张量(B x C x H x W)或相同大小的图像列表。其中C只能为1(黑白显示)或者3(彩色显示)
- nrow:网格中每行显示的图像数。最终栅格大小为(B/nrow,nrow);默认值:8。
- padding:图像间距(像素单位)
- normalize:是否将像素值标准化;如果为True,则将图像按range指定的最小值和最大值移动到范围(0,1)。默认值:False。
- range:标准化范围;tuple(min,max),其中min和max是数字,那么这些数字用于规范化图像。默认情况下,min和max输入张量的最小值和最大值。
- scale_each:是否单张图维度标准化;如果为True,则在一批图像中分别缩放每个图像,而不是在所有图像上缩放(最小值、最大值)。默认值:False。
- pad_value:padding的像素值
实验:
1 | import os |
输出图像:

2.1.7 实战二 :卷积核和特征图的可视化
下面是我们对alexnet前两个卷积层的卷积核可视化的结果:
1 | import torch.nn as nn |
打印输出:
1 | 0_convlayer shape:(64, 3, 11, 11) |
tensorboard的显示(同一行是一个卷积核的各个通道):


下面是我们对alexnet第一个卷积层的输出特征图可视化的结果
1 | import torch.nn as nn |
tensorboard的显示:

2.1.8 add_graph
1 | add_graph(model, |
功能:可视化模型计算图
- model:模型,必须是 nn.Module
- input_to_model:输出给模型的数据
- verbose:是否打印计算图结构信息
实验:
1 | import os |

2.2 torchsummary
1 | summary(model, |
功能:查看模型信息,便于调试
- model:pytorch模型
- input_size:模型输入size
- batch_size:batch size(缺省即可)
- device:“cuda” or “cpu”
通过pip install torchsummary安装torchsummary
device='cuda’有时候会报错
实验:
1 | from torchsummary import summary |
输出:
1 | ---------------------------------------------------------------- |