transforms方法详解

1. transforms——裁剪
实验代码:
1 | # -*- coding: utf-8 -*- |
1.1 transforms.CenterCrop
1 | torchvision.transforms.CenterCrop(size) |
功能:从给出的PIL图像中心裁剪图片
- size:所需裁剪图片尺寸
实验
1 | train_transform = transforms.Compose([ |
-
可以看到,图片已经从224x224剪裁为196x196了
![image-20200724134458082]()
-
如果将size设置为(224,196),效果如下图
![image-20200724134704745]()
-
如果将size设置为512,超过了原来224的尺寸,就会zero padding
![image-20200724134839744]()



1.2 transforms.RandomCrop
1 | torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant') |
功能:从图片中随机裁剪出尺寸为size的图片
- size:所需裁剪图片尺寸
- padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,左右填充a个像素,上下填充b个像素
当为(a, b, c, d)时,左,上,右,下分别填充a, b, c, d - pad_if_need:若图像小于设定size,则填充
- padding_mode:填充模式,有4种模式
- constant:像素值由fill设定
- edge:像素值由图像边缘像素决定
- reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4] → [3,2,1,2,3,4,3,2]
- symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] → [2,1,1,2,3,4,4,3]
- fill:constant时,设置填充的像素值
实验
-
程序如下,本实验分别打开注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 2 RandomCrop
transforms.RandomCrop(224, padding=16),
# transforms.RandomCrop(224+16*2, padding=16),
# transforms.RandomCrop(224, padding=(16, 64)),
# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),
# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True
# transforms.RandomCrop(224, padding=64, padding_mode='edge'),
# transforms.RandomCrop(224, padding=64, padding_mode='reflect'),
# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
选择
transforms.RandomCrop(224, padding=16),可以发现先做了上下左右16的zero padding,然后再随机裁剪224x224的区域。若执行transforms.RandomCrop(512, padding=16)则会报错,因为已经超过了原尺寸+padding的大小。![image-20200724140246505]()
-
选择
transforms.RandomCrop(224+16*2, padding=16)会发现,得到的就是原图片上下左右zero padding 16的结果,因为没得选了哈哈。![image-20200724140804559]()
-
选择
transforms.RandomCrop(224, padding=(16, 64)),发现填充的区域上下变宽,左右变窄。padding=一个int时,就是左右上下等宽,此外还可以接受一个二元组控制左右和上下,甚至可以接受一个四元组控制左、上、右、下。![image-20200724141354570]()
-
选择
transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),发现填充的像素变成了红色。实际上fill=(R, G, B)是一个RGB三元组,控制填充颜色。此外,如果fill=一个int,那么不是RGB三个通道都等于这个int哦,只是R通道等于这个int,GB通道是0。但是默认fill=0是确实又是RGB都为0,比较奇怪。使用时还是写三元组避免问题。![image-20200724141103792]()
-
选择
transforms.RandomCrop(512, pad_if_needed=True),就可以对大于图片尺寸的区域做随机剪裁了。(应该无论size多大,总会有原图像的全部像素在里面吧)![image-20200724143011081]()
-
选择
transforms.RandomCrop(224, padding=64, padding_mode='edge'),用最外的一圈像素padding。![image-20200724143206924]()
-
选择
transforms.RandomCrop(224, padding=64, padding_mode='reflect'),做反射填充(原图像最外一圈像素不镜像)![image-20200724143349581]()
-
选择
transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),做对称填充(原图像最外一圈像素也镜像)。其实padding_mode='symmetric'和padding_mode='reflect'的区别不大,仅一圈像素不同。![image-20200724143550692]()








1.3 RandomResizedCrop
1 | torchvision.transforms.RandomResizedCrop(size, |
功能:随机大小、长宽比裁剪图片
-
size:所需裁剪图片尺寸
-
scale:随机裁剪面积比例范围, 默认(0.08, 1)
-
ratio:随机长宽比范围,默认(3/4, 4/3)
-
interpolation:插值方法
PIL.Image.NEAREST (0)
PIL.Image.BILINEAR (2)
PIL.Image.BICUBIC (3)Default: PIL.Image.BILINEAR
实验
-
程序如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 3 RandomResizedCrop
transforms.RandomResizedCrop(size=224, scale=(0.08, 1), ratio=(1. / 4., 4. / 1.)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
输出结果
![image-20200724183908753]()
![image-20200724183930644]()
![image-20200724183938326]()
![image-20200724183948494]()




1.4 FiveCrop
1 | torchvision.transforms.FiveCrop(size) |
功能:将给定的PIL图像裁剪出左上、左下、右上、右下以及中央的五块区域
- size:每个图像的尺寸,如果size是一个int而不是(h, w)的,则生成一个大小(size, size)的正方形裁剪。
注意:此转换返回图像的元组,数据集返回的输入和目标数量可能不匹配

实验:
-
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 4 FiveCrop
transforms.FiveCrop(112),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
bs, ncrops, c, h, w = inputs.shape
for n in range(ncrops):
img_tensor = inputs[0, n, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(1) -
通过调试可以看到,inputs是一个shape为(1,5,3,112,112)的五维tensor。由于我们设置的batch-size=1,所以第一个维度的维数为1。这里我们通过
img_tensor = inputs[0, n, ...]将5张照片依次检索出来,并转成PIL图片显示。![image-20200724202242205]()
![image-20200724202815577]()
![image-20200724202848292]()
![image-20200724202904656]()
![image-20200724202912438]()
![image-20200724202920264]()






1.5 TenCrop
1 | torchvision.transforms.TenCrop(size, vertical_flip=False) |
功能:将给定的PIL图像裁剪成四个角以及中央部分,加上这些角的翻转版本(默认情况下使用水平翻转)
- size:所需裁剪图片尺寸
- vertical_flip:是否垂直翻转
和FiveCrop一样,也是返回一个含有10个PIL照片的元组
实验:
-
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 5 TenCrop
transforms.TenCrop(112, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
bs, ncrops, c, h, w = inputs.shape
for n in range(ncrops):
img_tensor = inputs[0, n, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(1) -
输出照片


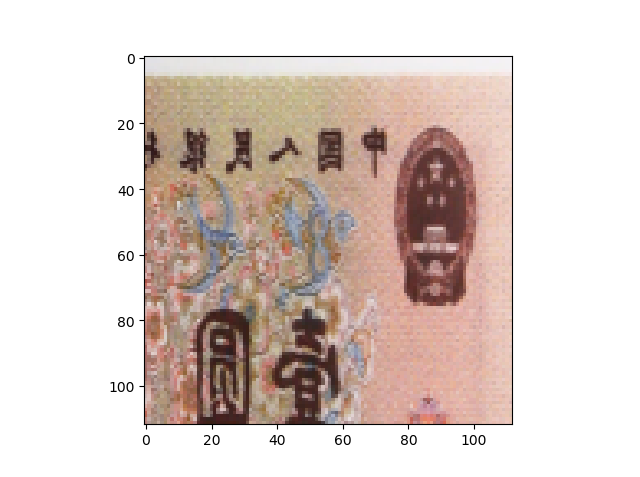

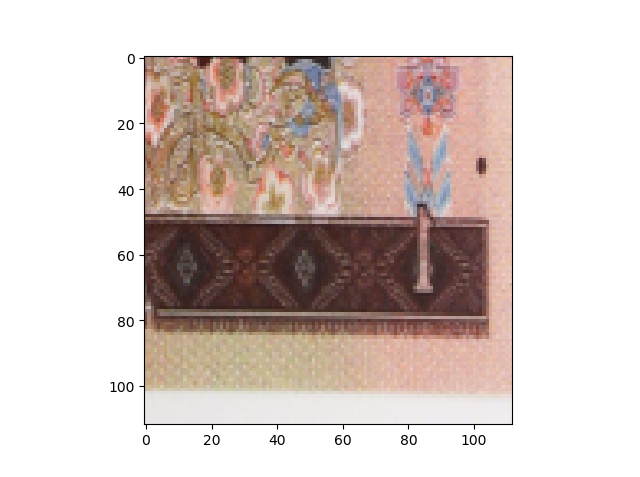
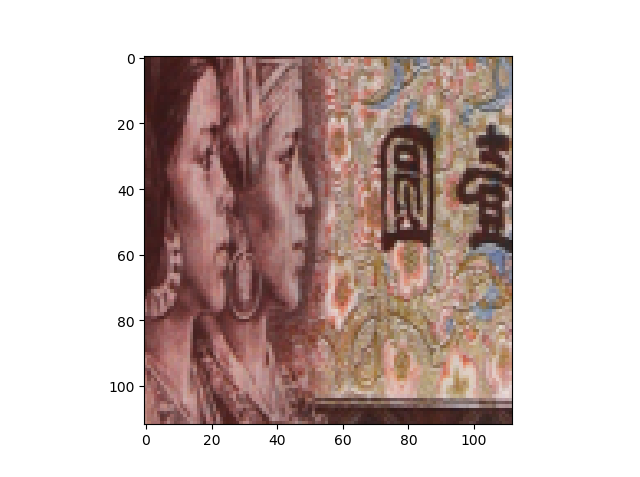
2. transforms——翻转、旋转
2.1 RandomHorizontalFlip
1 | torchvision.transforms.RandomHorizontalFlip(p=0.5) |
功能:以给定的概率 水平翻转给定的图像,图像可以是PIL图像或pytorch张量。
- p (float) – 图像被翻转的概率。默认值为0.5
实验:
-
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 Horizontal Flip
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
输出图像以0.5的概率水平翻转
![image-20200724211919150]()

2.2 RandomVerticalFlip
1 | torchvision.transforms.RandomVerticalFlip(p=0.5) |
功能:以给定的概率 上下翻转给定的图像,图像可以是PIL图像或pytorch张量。
- p (float) – 图像被翻转的概率。默认值为0.5
实验:
代码同上,只需要改写一句即可。输出图像按概率0.5上下翻转

2.3 RandomRotation
1 | torchvision.transforms.RandomRotation(degrees, resample=False, expand=False, center=None, fill=None) |
功能:随机旋转图片
- degrees:旋转角度
当为a时,在(-a,a)之间选择旋转角度
当为(a, b)时,在(a, b)之间选择旋转角度 - resample:重采样方法
- expand:是否扩大图片,以保持原图信息
- degrees:旋转角度
当为a时,在(-a,a)之间选择旋转角度
当为(a, b)时,在(a, b)之间选择旋转角度 - resample:重采样方法
- expand:是否扩大图片,以保持原图信息
- center:旋转点设置,默认中心旋转
注意:旋转之后,如果不设置expand=True,图片的信息会损失,但是图片尺寸不变。如果设置expand=Flase,图片的信息不会损失,但是图片尺寸改变。
实验:
-
主程序:分别打开注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 3 RandomRotation
transforms.RandomRotation(90),
# transforms.RandomRotation((90), expand=True),
# transforms.RandomRotation(30, center=(0, 0)),
# transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
选择
transforms.RandomRotation(90),图片以0.5的概率随机旋转(-90, 90)![image-20200724213627390]()
-
选择
transforms.RandomRotation((90), expand=True),图片以0.5的概率随机旋转(-90, 90),并且开启expand。![image-20200724213804568]()
-
选择
transforms.RandomRotation(30, center=(0, 0)),图片以0.5的概率随机绕左上角顶点旋转(-30, 30)。![image-20200724213945121]()
-
选择
transforms.RandomRotation(30, center=(0, 0), expand=True),图片以0.5的概率随机绕左上角顶点旋转(-30, 30),并且开启expand。我们发现expand并没有帮助我们保留图片的全部信息。其实expand是根据中心旋转的模式计算的padding范围,所以只有当绕中心旋转时,expand才有效。![image-20200724214025465]()




3. transforms ——图像变换
3.1 transforms.Pad
1 | torchvision.transforms.Pad(padding, fill=0, padding_mode='constant') |
功能:对图片边缘进行填充
- padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,左右填充a个像素,上下填充b个像素
当为(a, b, c, d)时,左,上,右,下分别填充a, b, c, d - padding_mode:填充模式,有4种模式,constant、edge、reflect和symmetric
- fill:constant时,设置填充的像素值,(R, G, B) or (Gray)
实验:
-
主程序:分别打开注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 Pad
transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='symmetric'),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
选择
transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode='constant'),发现上下左右都填充了宽度32的红色像素。![image-20200724230737668]()
-
选择
transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode='constant')![image-20200724230902441]()
-
选择
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='constant')![image-20200724230929961]()
-
选择
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='symmetric')![image-20200724230958489]()




3.2 transforms.ColorJitter
1 | torchvision.transforms.ColorJitter(brightness=0, |
功能:调整亮度、对比度、饱和度和色相
-
brightness:亮度调整因子
当为a时,从[max(0, 1-a), 1+a]中随机选择
当为(a, b)时,从[a, b]中 -
contrast:对比度参数,同brightness
-
saturation:饱和度参数,同brightness
-
hue:色相参数,
当为a时,从[-a, a]中选择参数,注: 0<= a <= 0.5
当为(a, b)时,从[a, b]中选择参数,注:-0.5 <= a <= b <= 0.5
-
主程序:分别打开注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 2 ColorJitter
transforms.ColorJitter(brightness=0.5),
# transforms.ColorJitter(contrast=0.5),
# transforms.ColorJitter(saturation=0.5),
# transforms.ColorJitter(hue=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
原图
![image-20200725114053978]()
-
选择
transforms.ColorJitter(brightness=0.5),图片亮度随机在(0.5, 1.5)之间变化。![image-20200725114342925]()
-
选择
transforms.ColorJitter(contrast=0.5),图片对比度随机在(0.5, 1.5)之间变化。![image-20200725132214278]()
-
选择
transforms.ColorJitter(saturation=0.5),图片饱和度随机在(0.5, 1.5)之间变化。![image-20200725132321875]()
-
选择
transforms.ColorJitter(hue=0.5),图片色度随机在(0.5, 1.5)之间变化。![image-20200725132345791]()





3.3 transforms.Grayscale
1 | torchvision.transforms.Grayscale(num_output_channels=1) |
功能:将图片转换为灰度图
参数:
- num_output_channels (int) – (1 or 3) 输出图像所需的通道数
返回值:PIL图像
- If
num_output_channels == 1: 返回单通道图像 - If
num_output_channels == 3: 返回 r == g == b的三通道图像
-
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 3 transforms.Grayscale
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
输出图像
![image-20200725144037942]()

3.4 transforms.RandomGrayscale
1 | torchvision.transforms.RandomGrayscale(p=0.1) |
功能:依概率将图片转换为灰度图
- p:概率值,图像被转换为灰度图的概率
和3.3没什么区别,多了一个概率而已,代码和实验跳过
3.5 transforms.RandomAffine
1 | torchvision.transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0) |
功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转
- degrees:旋转角度设置
- translate:平移区间设置,如(a, b), a设置宽(width),b设置高(height)图像在宽维度平移的区间为 -img_width * a < dx < img_width * a
- scale:缩放比例(以面积为单位)
- fill_color:填充颜色设置
- shear:错切角度设置,有水平错切和垂直错切
若为a,则仅在x轴错切,错切角度在(-a, a)之间
若为(a,b),则a设置x轴角度,b设置y的角度
若为(a, b, c, d),则a, b设置x轴角度,c, d设置y轴角度 - resample:重采样方式,有NEAREST 、BILINEAR、BICUBIC
实验:
-
主程序:分别打开注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 4 Affine
transforms.RandomAffine(degrees=30),
# transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)),
# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)),
# transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)),
# transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
选择
transforms.RandomAffine(degrees=30),图像随机旋转(-30, 30)![image-20200725145211665]()
![image-20200725145227441]()
![image-20200725145211665]()
-
选择
transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)),图像随机左右,上下平移0.2倍图像的框和高,并用红色像素填充。![image-20200725145855139]()
![image-20200725145911179]()
![image-20200725145926095]()
-
选择
transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)),缩放0.7倍(掐死区间了,就随机不起来了)![image-20200725150143359]()
-
选择
transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)),图像在y方向错切(0, 45)![image-20200725151254855]()
![image-20200725151314294]()
![image-20200725151327432]()
-
选择
transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)),图像在x方向错切(-90, 90),并用红色像素填充。![image-20200725151557434]()
![image-20200725151610443]()
![image-20200725151619749]()












3.6 transforms.RandomErasing
1 | torchvision.transforms.RandomErasing(p=0.5, |
功能:对图像进行随机遮挡
-
p:概率值,执行该操作的概率
-
scale:遮挡区域的面积
-
ratio:遮挡区域长宽比
-
value:设置遮挡区域的像素值,(R, G, B) or (Gray)
如果设置为’random’,那么将会用正态分布像素值遮挡(其实value=字符型都是这样的)
注意:此函数操作的对象是tensor,因此需要先将PIL图片转换为tensor
实验:
-
主程序:分别打开注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 5 Erasing
transforms.ToTensor(),
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.5, 1), value=(245/255, 0, 0)),
# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.5, 1), value='random'),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
选择
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.5, 1), value=(245/255, 0, 0)),随机选择(0.02, 0.33)倍的原图像面积区域进行遮挡,遮挡区域长宽比随机范围为(0.5, 1),填充的颜色RGB=(245/255, 0, 0)。注意,由于已经是tensor了,所以应该用(0, 1)的tensor浮点数来表示RGB各通道的值。![image-20200725153031251]()
![image-20200725153042761]()
![image-20200725153053195]()
-
选择
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.5, 1), value='random'),遮挡区域变成了正态分布随机像素值![image-20200725154216327]()
![image-20200725154226970]()
![image-20200725154237085]()






3.7 transforms.Lambda
1 | torchvision.transforms.Lambda(lambd) |
功能:用户自定义lambda方法
-
lambd:lambda匿名函数
lambda [arg1 [,arg2, … , argn]] : expression
用于在变换中,自定义变化方法。之前我们在FiveCrop和TenCrop中也使用过。
1 | transforms.Lambda(lambda crops: torch.stack([transforms.Totensor()(crop) for crop in crops])) |
4. transforms ——transforms方法操作
4.1 transforms.RandomChoice
1 | torchvision.transforms.RandomChoice([transforms1, transforms2, transforms3]) |
功能:从列表中随机选取一个transforms操作
实验:
-
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 RandomChoice
transforms.RandomChoice([transforms.RandomVerticalFlip(p=1), transforms.RandomHorizontalFlip(p=1)]),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
输出图像(顺序选取前三张)
![image-20200727133941261]()
![image-20200727133950640]()
![image-20200727134010346]()



4.2 transforms.RandomApply
1 | torchvision.transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5) |
功能:依据概率执行一组transforms操作
实验:
-
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 2 RandomApply
transforms.RandomApply([transforms.RandomAffine(degrees=0, shear=45, fillcolor=(255, 0, 0)), transforms.Grayscale(num_output_channels=3)], p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
输出图像(顺序选取前三张)
![image-20200727134645204]()
![image-20200727134728527]()
![image-20200727134746055]()



4.3 transforms.RandomOrder
1 | transforms.RandomOrder([transforms1, transforms2, transforms3]) |
功能:对一组transforms操作打乱顺序
实验:
-
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 3 RandomOrder
transforms.RandomOrder([transforms.RandomRotation(5), transforms.Pad(padding=32), transforms.RandomAffine(degrees=0, translate=(0.01, 0.1), scale=(0.9, 1.1))]),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
输出图像(顺序选取前三张)
![image-20200727135214233]()
![image-20200727135227157]()
![image-20200727135240011]()



5. 自定义transforms方法
自定义transforms要素:
-
仅接收一个参数,返回一个参数
-
注意上下游的输出与输入
1
2
3
4
5class Compose(object):
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img由于transforms是在
class Compose的__call__(self, img)中通过一个for循环实现的,因此需要注意上一个transform的输出是现在的transform的输入,前后数据类型需要匹配。
自定义transform通过类实现多参数传入:
1 | class YourTransforms(object): |
实验:
以自定义一个生成椒盐噪声的transform为例
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点, 白点称为盐噪声,黑色为椒噪声
信噪比(Signal-Noise Rate, SNR)是衡量噪声的比例,图像中为图像像素的占比


-
自定义transform的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class AddPepperNoise(object):
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) or (isinstance(p, float))
self.snr = snr
self.p = p
def __call__(self, img):
if random.uniform(0, 1) < self.p:
img_ = np.array(img).copy()
h, w, c = img_.shape
signal_pct = self.snr
noise_pct = 1 - self.snr
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2, noise_pct/2]) # 从0,1,2中按概率选取,形成size形状的ndarray
mask = np.repeat(mask, c, axis=2) # 按第三个维度,也就是通道数重复2
img_[mask == 1] = 255 # 椒噪声
img_[mask == 2] = 0 # 盐噪声
return Image.fromarray(img_.astype('uint8')).convert("RGB")
else:
return img -
主程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 4 自定义transforms
AddPepperNoise(0.8, p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# ============================ step 2/2 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close() -
输出图像(顺序选取前三张):
![image-20200727144319495]()
![image-20200727144336806]()
![image-20200727144348026]()


